Google Announces Cloud TPU v2 Beta Availability for Google Cloud Platform
by Nate Oh on February 15, 2018 7:30 AM EST
This week, Google announced Cloud TPU beta availability on the Google Cloud Platform (GCP), accessible through their Compute Engine infrastructure-as-a-service. Using the second generation of Google’s tensor processing units (TPUs), the standard Cloud TPU configuration remains four custom ASICs and 64 GB of HBM2 on a single board, intended for accelerating TensorFlow-based machine learning workloads. With a leased Google Compute Engine VM, Cloud TPU resources can be used alongside current Google Cloud Platform CPU and GPU offerings.

First revealed at Google I/O 2016, the original TPU was a PCIe-based accelerator designed for inference workloads, and for the most part, the TPUv1 was used internally. This past summer, Google announced the inference and training oriented successor, the TPUv2, outlining plans to incorporate it into their cloud services. Both were detailed later at Hot Chips 2017 technical presentations.
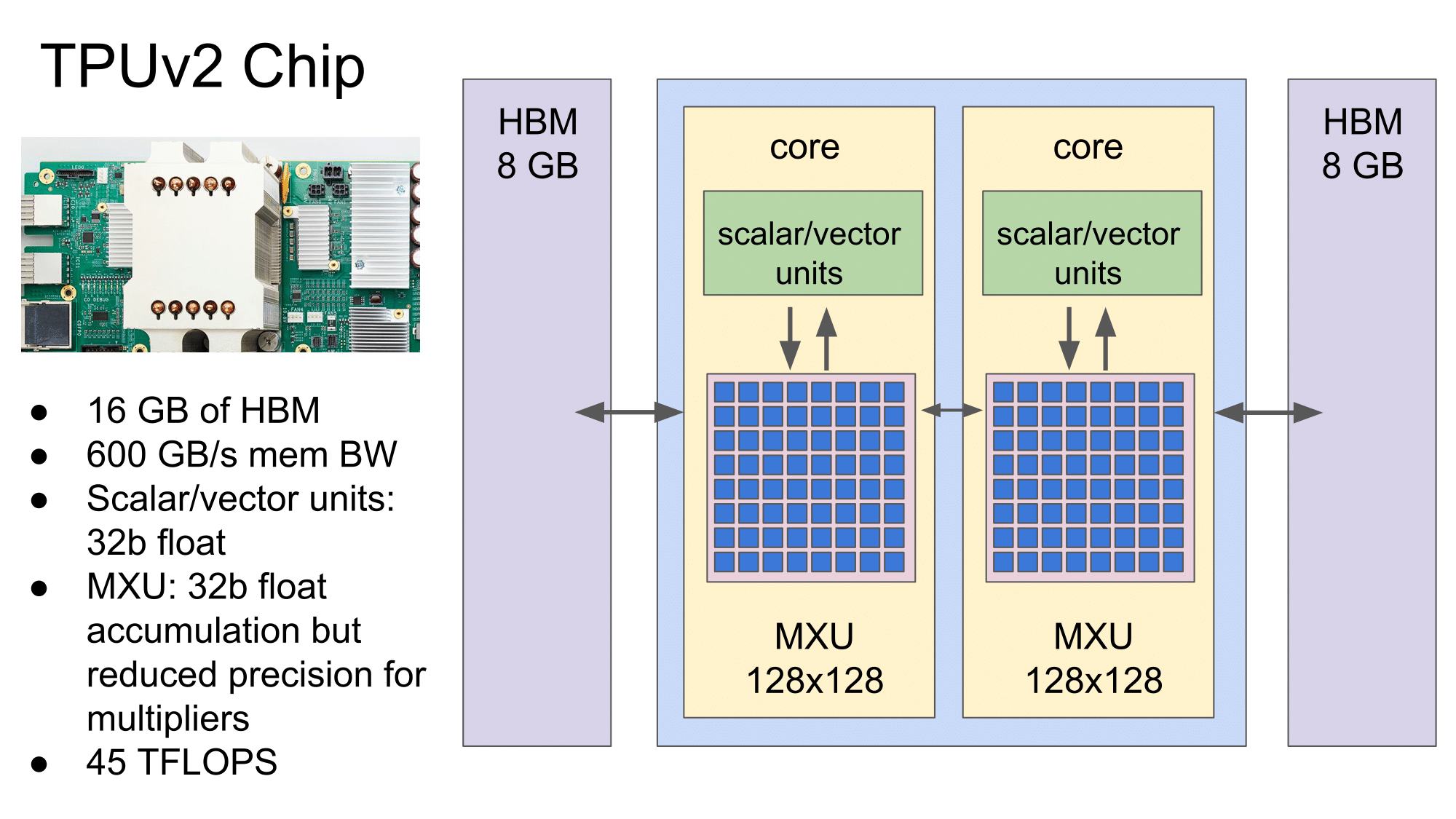
Under the hood, the TPUv2 features a number of changes. Briefly recapping, the second generation TPU ASIC comes with a dual ‘core’ configuration, each having a scalar/vector unit and 128x128 mixed multiply unit capable of 32-bit floating point operations, as opposed to TPUv1’s single core 256x256 MXU and 8-bit integer capability. TPUv2 also improves on the memory bandwidth bottlenecks of its predecessor by using HBM instead of DDR3, with 8GB HBM2 connected to each core for a total of 16 GB per chip.

Four of these ASICs form a single Cloud TPU board, ultimately with Google citing up to 180 TFLOPS of unspecified compute performance. As announced earlier, Google is targeting a ‘TPU pod’ setup as one of the end goals, where 64 Cloud TPUs are combined in a dedicated networked array of racks. Google is aiming to offer full TPU Pods on GCP later this year.
In practical terms, this capability is catered to developers looking for TPU-suitable machine learning performance for particular TensorFlow workloads, with the benefit of Google’s existing cloud infrastructure-as-a-service offerings. Given that it is a beta, Google has a number of documents and tools up on their site. In many ways, the current TPU capabilities exist as a development pipe-cleaner of sorts for the upcoming TPU pods, with Google alluding to the same thing in their announcement. A number of capabilities are yet to be ironed out for TPUs: for example, model parallelism is not yet supported, not all built-in TensorFlow ops are available, and specific limitations exist for training reinforcement learning models, recurrent neural networks (RNN), or generative adversarial networks (GAN).
While select partners have had access to Cloud TPUs for production use, today’s announcement opens the availability to general GCP customers. Google’s Cloud TPUs are available today as purchasable compute time in the US from a Compute Engine provisioned VM, with a $6.50 per TPU per hour rate charged in one-second increments. Interested parties may submit a beta quota request.
Related Reading
Source: Google Cloud








8 Comments
View All Comments
Threska - Thursday, February 15, 2018 - link
One second increments for a per hour charge? Plus at those rates there's going to be some job packing.CiccioB - Thursday, February 15, 2018 - link
Few questions:1. power consumption of one of this thing?
2. is the HBM mounted on the motherboard instead of being placed on the same package next to the TPU?
3. the slide says that the accumulator is a 32b register but the precision is reduced for the multipliers, so it does not seem those are 128x128 real 32bit capable multipliers (16x16 or 24x24 maybe)
4. how does that compare in real performance (theoretic TFLOPS aside) with other AI computing devices like the monster (in all senses) GV100? Some tests?
5. Can it mine bitcoins or ethereums? :D
Yojimbo - Saturday, February 17, 2018 - link
You can get the answer to 1 and 2 in various Next Platform articles. As far as how the tpu2 compares to the GV100 in real world perfomance and price/performance, you can find some limited data here: https://www.forbes.com/sites/moorinsights/2018/02/...No, you can't mine bitcoin or ether. You can't even deal with non-TensorFlow neural networks.
MrSpadge - Thursday, February 15, 2018 - link
So that's where all the HBM went, leaving none for AMDs big Vega.Yojimbo - Saturday, February 17, 2018 - link
I don't think they are using all that much HBM for their pods. Maybe they have built more, but from what ai remember, they initially had 3 pods. Each pod has 256 TPUs if I remember. That's 768 TPUs each with 16 GB of HBM2. That's a piddly amount compared to what NVIDIA has used in their production of the Tesla P100, Quadro P100, Tesla V100, and Titan V.Yojimbo - Saturday, February 17, 2018 - link
Sorry, I misremembered. There are 256 TPUs in a rack. There are 4 racks in a pod. So there are 1024 TPUs in a pod and 3072 in the three pods.As a comparison, just one supercomputer that uses the Tesla P100, piz daint, uses 5320 P100s, each with 16 GB of HBM2. The vast majority of P100s and V100s are being used by companies for deep learning, and not in supercomputers.
mode_13h - Tuesday, February 20, 2018 - link
If you just consider raw computational power, I wonder how that picture compares to a mammalian brain.MonicaJB - Monday, June 15, 2020 - link
Great article! I want to share my passion with you. I love online slots. It relaxes me, helps me get distracted. You can find my favorite slot machine Book of Ra at this link https://book-of-ra-play.com/how-to-win-on-slot-boo... What are your favorite online slots?