Khronos Group Launches the Neural Network Exchange Format
by Nate Oh on December 20, 2017 9:00 AM EST- Posted in
- Neural Networks
- Khronos
- Machine Learning
- Deep Learning
- AI
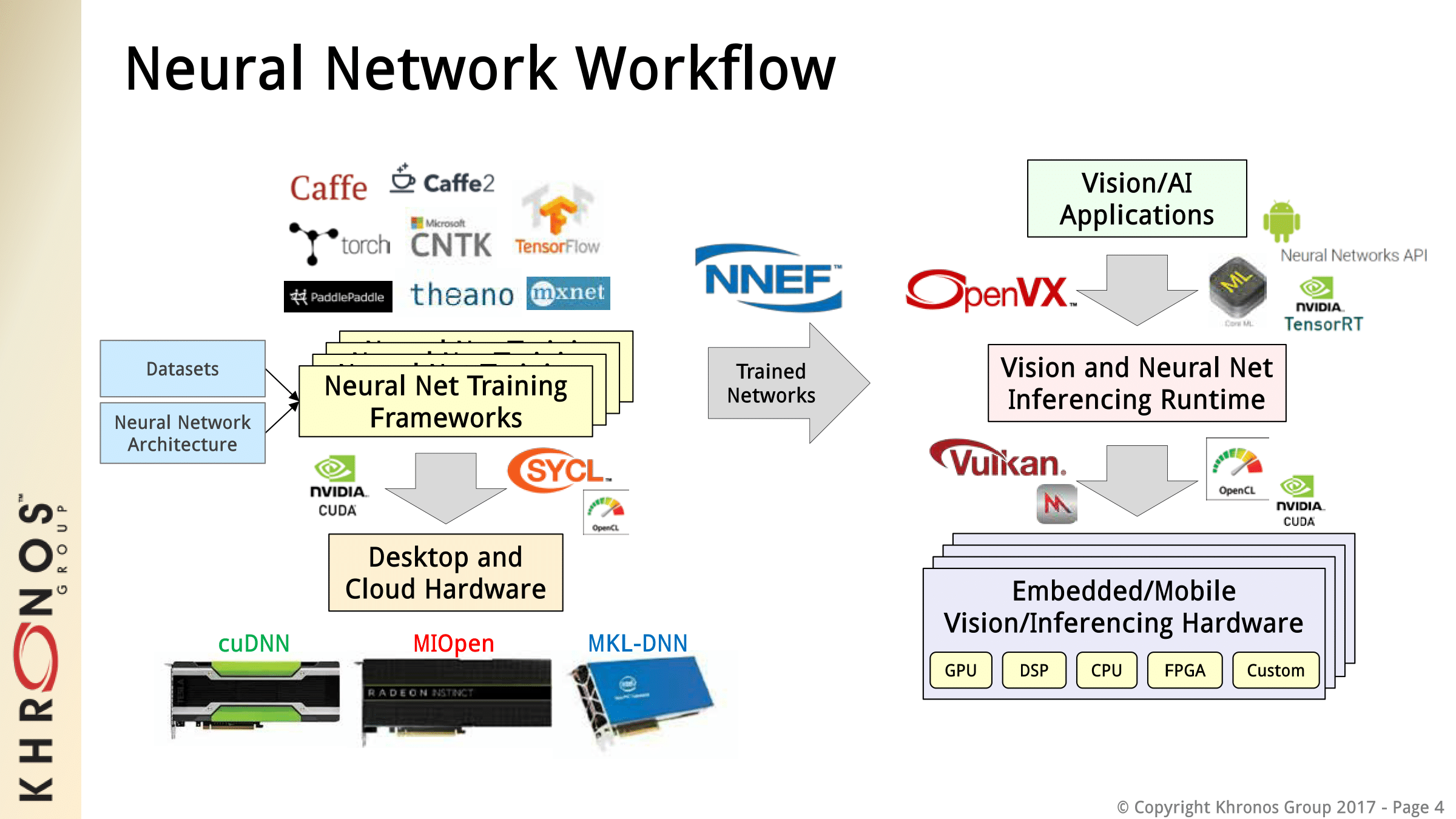
Today the Khronos Group, the industry consortium behind OpenGL and Vulkan, released a v1.0 provisional specification for its Neural Network Exchange Format (NNEF). First announced last year, this provisional stage is aimed at getting industry feedback on real-world use. While its name encapsulates its purpose, more specifically NNEF will act as a compatible format that can transfer trained neural networks between frameworks or to a wide range of inferencing hardware. Khronos is hoping that NNEF will act as a common format for all the myriad frameworks, such as Caffe, TensorFlow, Theano, and Torch, and be as ubiquitous in neural network porting in the same way PDFs are used for documents.

Much of the strength of NNEF comes from its bifurcated file structure, where there is a general and compatible flat level along with a complicated and optimizable compositional level. NNEF has also been designed with the understanding that deep learning is still a young and rapidly advancing field, where certain AI or neural network methods or framework types may become quickly displaced.
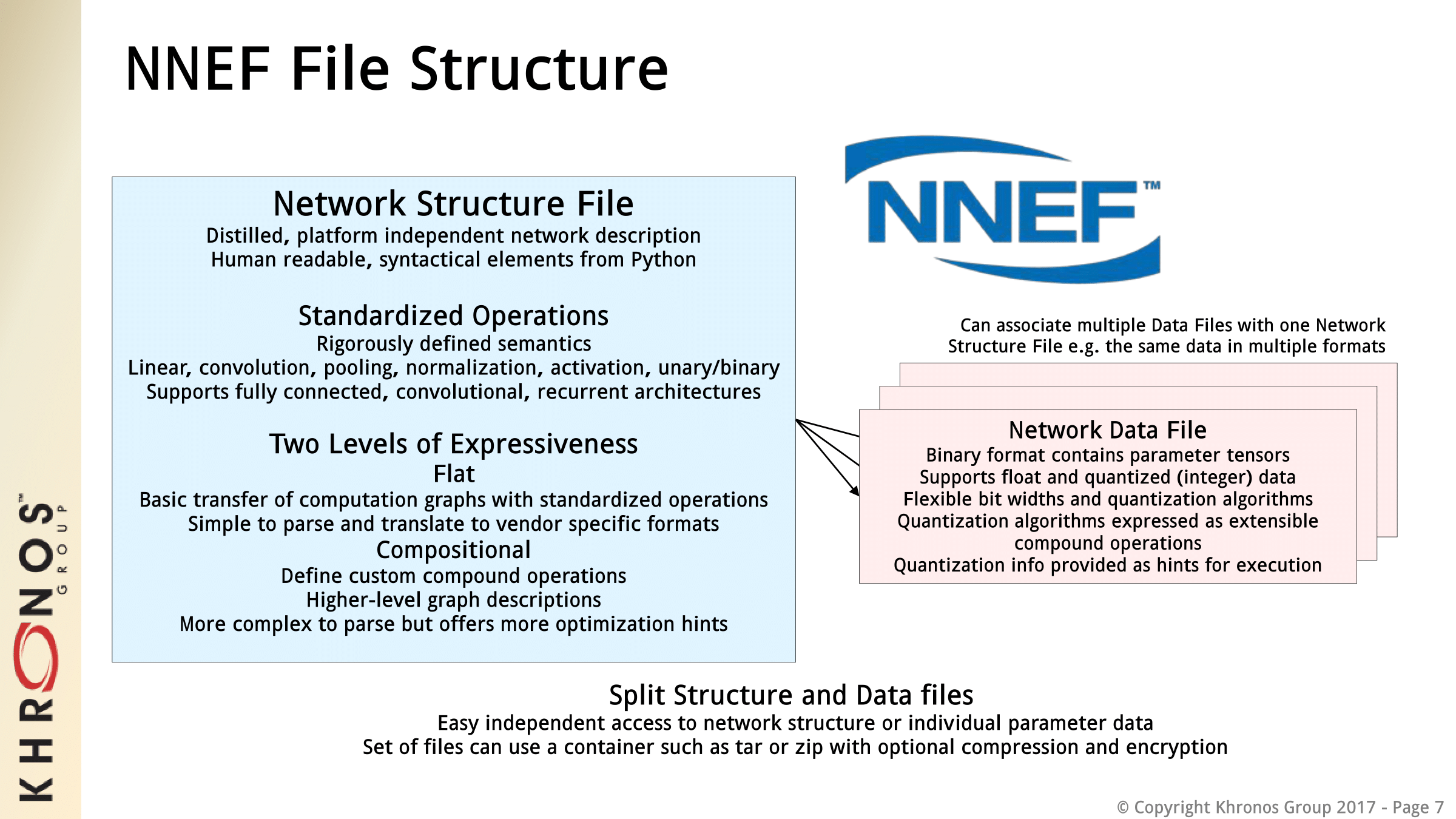
NNEF will also complement Khronos’ OpenVX, a high-level graph-based API intended for cross-platform use in computer vision, and both working groups have already been collaborating. The upcoming releases of OpenVX will feature a NNEF Import extension, which would provide more flexibility to the format. As a specification, NNEF does not include tools, and Khronos is pursuing an open source strategy, with current projects on an NNEF syntax parser/validator and exporters for specific frameworks.
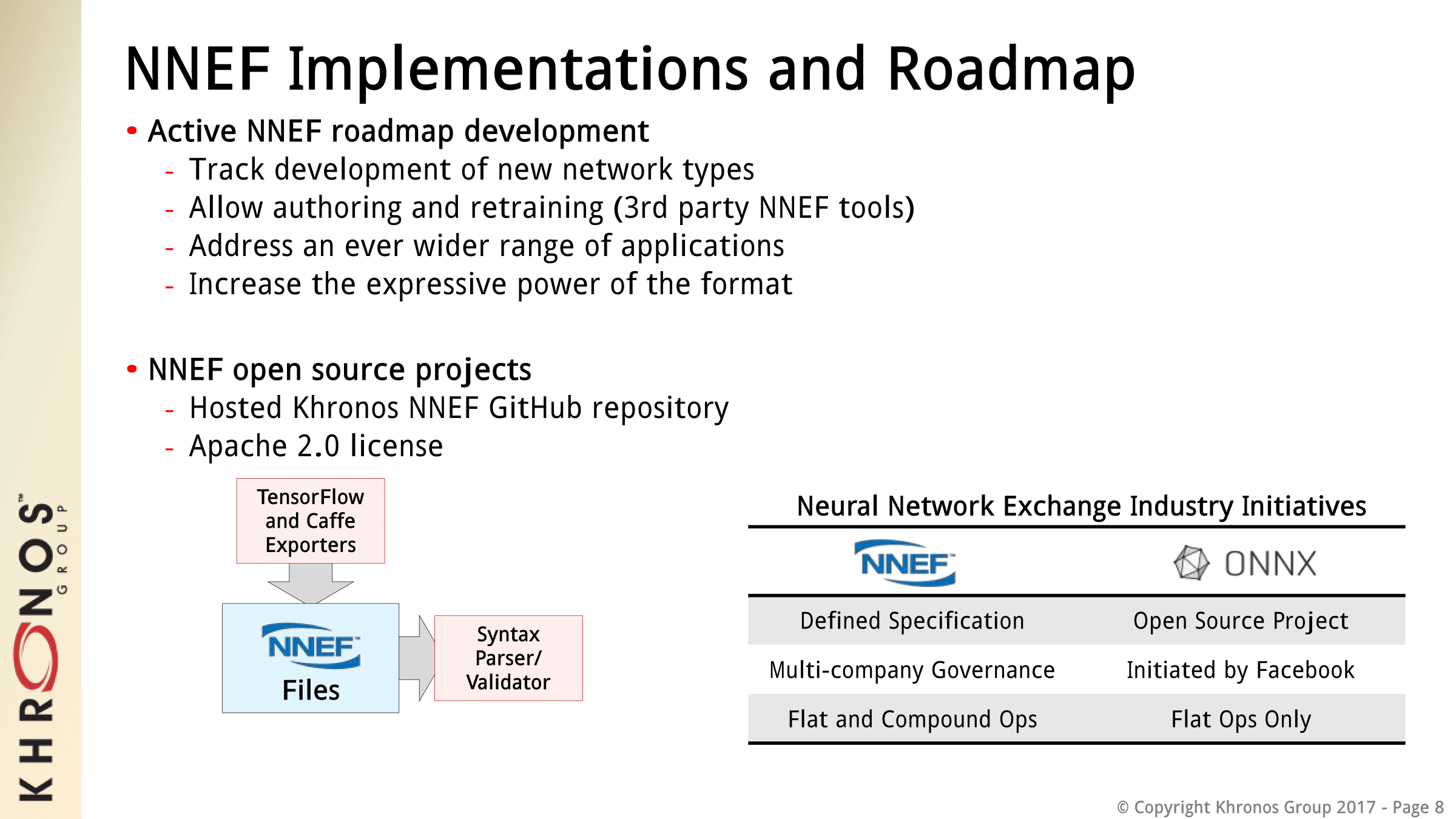
This approach contrasts with the similar Open Neural Network Exchange (ONNX) started by Facebook and Microsoft, where the format specification is essentially part of the open source project. NNEF itself is a standardized specification, with open source projects complementing it.
Overall, Khronos identifies two general use-cases for NNEF: for using a given trained network with a given inferencing engine, and for transposing a trained network from one framework to another. The former has been the focus and NNEF is being developed with silicon vendors in mind. A static standardized specification is particularly useful for hardware manufacturers, and NNEF’s two-level data topology allows silicon designers to optimize for their specific hardware via the custom compound operations capability.
On that note, this launch of the provisional specification is not limited to manufacturers, and Khronos is looking for the industry feedback to refine their specification and its strongest use-cases for a final release. Khronos has noted that framework-to-framework transposition might be one of several avenues that researchers could explore on their own as part of the open source projects.
While NNEF has no set date to be finalized, Khronos mentioned that a 3 to 6 month period before finalization would be typical.
More project details can be found on the NNEF GitHub repository.





Source: Khronos Group








8 Comments
View All Comments
edzieba - Wednesday, December 20, 2017 - link
That headline reads like one of the Secret Project achievements from Sid Meier's Alpha Centauri.p1esk - Wednesday, December 20, 2017 - link
Well, that's a noble goal, but are the major frameworks interested?mode_13h - Thursday, December 21, 2017 - link
Thankfully, they don't need to be. Even if the maintainers refuse any patches to add native NNEF support, they can't prevent you from using tools that convert between their formats and NNEF.p1esk - Friday, December 22, 2017 - link
Ok, but who will write the conversion code? Or, which companies benefit from this?mode_13h - Friday, December 22, 2017 - link
Here's a link from the article:https://github.com/KhronosGroup/Khronosdotorg/blob...
And I think it's reasonable to assume some popular frameworks will accept PRs to directly integrate NNEF support.
alfalfacat - Thursday, December 21, 2017 - link
Conspicuously absent from the NNEF Working Group: Google, Microsoft, Facebook, Apple, Baidu, etc.You know, the people actually spending billions writing TF/CNTK/Caffe2, building custom hardware accelerators, and using it in production?
mode_13h - Thursday, December 21, 2017 - link
Yeah, so what?Of course Google wants the whole world to use TensorFlow and FaceBook would rather they all use Caffe2. Neither has much to gain by making it easy to convert between them, but their cooperation is unnecessary.
There are plenty of big players in the WG, both at the bottom (hardware) and top (apps) of the stack. They have basically all GPU designers except for Nvidia: AMD, ARM, Imagination, Intel, and Qualcomm. Add to that some FPGA and deep learning silicon vendors. At the top of the stack, they have AIMotive and Axis. There are also several middleware & tools vendors.
More than enough folks who know what they're doing and have a vested interest in it succeeding. I don't know why you're throwing shade, but you're wasting your breath.
snapch23 - Friday, December 29, 2017 - link
It is so easy easy to have the shadow fight cheats online here. http://sf3hack.com