TechInsights Confirms Apple’s A10X SoC Is TSMC 10nm FF; 96.4mm2 Die Size
by Ryan Smith on June 29, 2017 11:30 PM EST
One of the more intriguing mysteries in the Apple ecosystem has been the question over what process the company would use for the A10X SoC, which is being used in the newly launched 2017 iPad Pro family. Whereas the A10 used in the iPhone was much too early to use anything but 16nm/14nm, the iPad Pro and A10X is coming in the middle of the transition point for high-end SoCs. 16nm is still a high performance process, but if a company pushes the envelope, 10nm is available. So what would Apple do?
The answer, as it turns out, is that they’ve opted to push the envelope. The intrepid crew over at TechInsights has finally dissected an A10X and posted their findings, giving us our first in-depth look at the SoC. Most importantly then, TechInsights is confirming that the chip has been fabbed on TSMC’s new 10nm FinFET process. In fact, the A10X is the first TSMC 10nm chip to show up in a consumer device, a very interesting turn of events since that wasn’t what various production roadmaps called for (that honor would have gone to MediaTek’s Helio X30)

Image Courtesy TechInsights
Apple is of course known for pushing the envelope on chip design and fabrication; they have the resources to take risks, and the profit margins to cover them should they not pan out. Still, that the A10X is the first 10nm SoC is an especially interesting development because it’s such a high-end part. Traditionally, smaller and cheaper parts are the first out the door as these are less impacted by the inevitable yield and capacity challenges of an early manufacturing node. Instead, Apple seems to have gone relatively big with what amounts to their 10nm pipecleaner part.
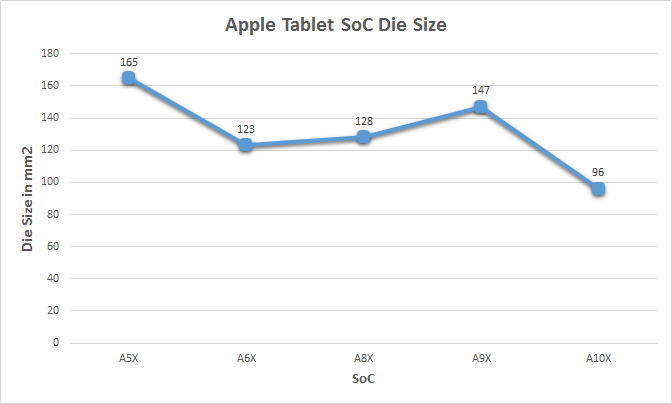
I say “relatively big” here because while the A10X is a powerful part, and big for a 10nm SoC, in terms of absolute die size it’s not all that big of a chip. In fact by Apple X-series SoC standards, it’s downright small: just 96.4mm2. This is 24% smaller than the 16nm A10 SoC (125mm2), and in fact is even 9% smaller than the A9 SoC (104.5mm2). So not only is it smaller than any of Apple’s 16nm SoCs, but it’s also about 20% smaller than the next-smaller X-series SoC, the A6X. Or, if you want to compare it to the previous A9X, Apple’s achieved a 34% reduction in die size. In other words, Apple has never made an iPad SoC this small before.
One key difference here however is that the X-series SoCs have never before been the leading part for a new process node. It has always been iPhone SoCs that have lead the charge – A9 at 16nm, A8 at 20nm, A7 at 28nm, etc. This does mean that as a pipecleaner part, Apple does need to be especially mindful of the risks. If an X-series SoC is to lead the charge for the 10nm generation, then it can’t be allowed to be too big. Not that this has stopped Apple from packing in three CPU cores and a 12-cluster GPU design.
Speaking of size, TechInsights’ estimates for area scaling are quite interesting. Based on their accounting, they believe that Apple has achieved a 45% reduction in feature size versus 16nm, which is consistent with a full node’s improvement. This is consistent with TSMC’s earlier statements, but given the challenges involved in bringing newer processes to market, it’s none the less exciting to actually see it happening. For chip vendors designing products against 10nm and its 7nm sibling, this is good news, as small die sizes are the rule for pretty much everyone besides Apple.
A10X Architecture: A10 Enlarged
Diving a bit deeper, perhaps the biggest reason that A10X is as small as it is, is that Apple seems to have opted to be conservative with its design. Which again, for a pipecleaner part, is what you’d want to do.
| Apple SoC Comparison | ||||||
| A10X | A9X | A8X | A6X | |||
| CPU | 3x Fusion (Hurricane + Zephyr) |
2x Twister | 3x Typhoon | 2x Swift | ||
| CPU Clockspeed | ~2.36GHz | 2.26GHz | 1.5GHz | 1.3GHz | ||
| GPU | 12 Cluster GPU | PVR 12 Cluster Series7 | Apple/PVR GXA6850 | PVR SGX554 MP4 | ||
| Typical RAM | 4GB LPDDR4 | 4GB LPDDR4 | 2GB LPDDR3 | 1GB LPDDR2 | ||
| Memory Bus Width | 128-bit | 128-bit | 128-bit | 128-bit | ||
| Memory Bandwidth | TBD | 51.2GB/sec | 25.6GB/sec | 17.1GB/sec | ||
| L2 Cache | 8MB | 3MB | 2MB | 1MB | ||
| L3 Cache | None | None | 4MB | N/A | ||
| Manufacturing Process | TSMC 10nm FinFET | TSMC 16nm FinFET | TSMC 20nm | Samsung 32nm | ||
We know from Apple’s official specifications that the A10X has 3 Fusion CPU core pairs, up from 2 pairs on A10, and 2 Twister CPU cores on A9X, all with 8MB of L2 cache tied to the CPU. Meanwhile the GPU in A10X is relatively unchanged; A9X shipped with a 12 cluster GPU design, and so does A10X. This means that Apple hasn’t invested their die space gains from 10nm in much of the way of additional hardware. To be sure, it’s not just a smaller A9X, but it’s also not the same kind of generational leap that we saw from A8X to A9X or similar iterations.
Unfortunately TechInsights’ public die shot release isn’t quite big enough or clean enough to draw a detailed floorplan from, but at a very high level we can make out the 12 GPU clusters on the left, along with the CPU cores to the right. Significantly, there aren’t any real surprises here. TechInsights heavily compares it to the A9X and there’s good reason to do so. IP blocks have been updated, but the only major change is the CPU cores, and those don’t take up a lot of die space relative to the GPU cores. This is what allows A10X to be more powerful than A9X while enjoying such a significant die size decrease.
As for the GPU in particular, Apple these days is no longer officially specifying whether they’re using Imagination’s PowerVR architecture in their chips. Furthermore we know that Apple is developing their own GPU, independent from Imagination’s designs, and that it will be rolled out sooner than later. With that said, even prior to today’s die shot release it’s been rather clear that A10X is not that GPU, and the die shot further proves that.
Apple’s developer documentation has lumped in the A10X’s GPU with the rest of the iOS GPU Family 3, which comprises all of the A9 and A10 family SoCs. So from a feature-set perspective, A10X’s GPU isn’t bringing anything new to the table. As for the die shot, as TechInsights correctly notes, the GPU clusters in the A10X look almost exactly like the A9X’s clusters (and the A10’s, for that matter), further indicating it’s the same base design.

Image Courtesy TechInsights
Ultimately what this means is that in terms of design and features, A10X is relatively straightforward. It’s a proper pipecleaner product for a new process, and one that is geared to take full advantage of the die space savings as opposed to spending those savings on new features/transistors.
Otherwise I am very curious as to just what this means for power consumption – is Apple gaining much there, or is it all area gains? A10X's CPU clockspeed is only marginally higher than A9X's, and pretty much identical to A10, so we can see that Apple hasn't gained much in the way of clockspeeds. So does that mean that Apple instead invested any process-related gains in reducing power consumption, or, as some theories go, has 10nm not significantly improved on power consumption versus 16nm? But the answer to that will have to wait for another day.
Source: Capped A10X Photo Courtesy iFixit








87 Comments
View All Comments
III-V - Friday, June 30, 2017 - link
That's a beefy L2Kevin G - Friday, June 30, 2017 - link
Helpful to keep the memory bus powered down more often, not explicitly for raw performance gains (though it helps there too). 8 MB on a mobile SoC is still a lot of cache.thesandbenders - Saturday, July 1, 2017 - link
The RAM is DDR, if you power it down you lose your data. A larger L2 does let you run the the RAM at a lower clock speed with less perceived performance impact for the user. A lower clock speed will generally lower power consumption.Nokiya Cheruhone - Tuesday, July 4, 2017 - link
I see you have no clue about how DDR-SDRAM works.thesandbenders - Tuesday, July 4, 2017 - link
I didn't realize "powered down" was commonly used to refer to idle and LP states, I stand corrected.name99 - Friday, June 30, 2017 - link
Not really. It only seems large compared to recent Intel designs which have focussed on having large L3 and small (but low-latency and high throughput L2).Compare with Penryn, for example, in 2007, which gave 3MiB to each core. Apple is giving 2.67MiB to each core --- basically the same sort of capacity.
The main thing to take away, I think, is that the exact details of a cache system (even at the most basic level of the sizes and the inclusivity) don't have a single correct answer --- the space of "good design" is fairly voluminous, and it doesn't take much of a change in exactly what you're trying to optimize for to shift the design in a way that looks substantial, but is still only a percent or so different in performance.
Santoval - Sunday, July 2, 2017 - link
I believe he implicitly (yet very obviously) meant "... for a mobile SoC". Your comparison is from an entirely different product category, so it really makes no sense.Eug - Friday, June 30, 2017 - link
First!...to 10 nm FF
StevoLincolnite - Friday, June 30, 2017 - link
It is not a real 10nm process.RPE33 - Friday, June 30, 2017 - link
Fake news confirmed by StevoLincolnite!!!