Imagination Announces PowerVR Furian GPU Architecture: The Next Generation of PowerVR
by Ryan Smith on March 8, 2017 11:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- SoCs
- Furian
Taking place today is Imagination Technologies’ annual tech summit in Santa Clara, California. The company’s annual summit is always a venue for major Imagination news, and this year that’s particularly the case. As the cornerstone of this year’s summit, Imagination is announcing their next PowerVR GPU architecture: Furian.
Furian marks the first new GPU architecture out of Imagination in almost 7 years. Rogue, the company’s first OpenGL ES 3.x-capable architecture, was first announced in 2010 and has become the cornerstone of Imagination’s entire GPU lineup, from wearables to high-end devices. In the intervening years, Imagination has made a number of smaller updates and optmizations to the architecture, leading to the 6, 7, and 8 series of PowerVR GPU designs. Now the company is undertaking a more radical revision to their architecture in the form of Furian, which like Rogue before it, will ultimately become the cornerstone of their GPU families.
I’ll have a deeper dive into Furian next week, but for today’s launch I want to hit the highlights of the new architecture and what Imagination’s goals are for the GPUs that will be derived from it. On that note, Imagination is not announcing any specific GPU designs today; while close partners already have beta RTL designs, the final designs and the announcement of those designs will come later in the year. But as the mobile industry is a bit more open in terms of design information due to the heavy use of IP licensing and the long design windows, it makes sense for Imagination to start talking this architecture up now, so that developers know what’s coming down the pipe.
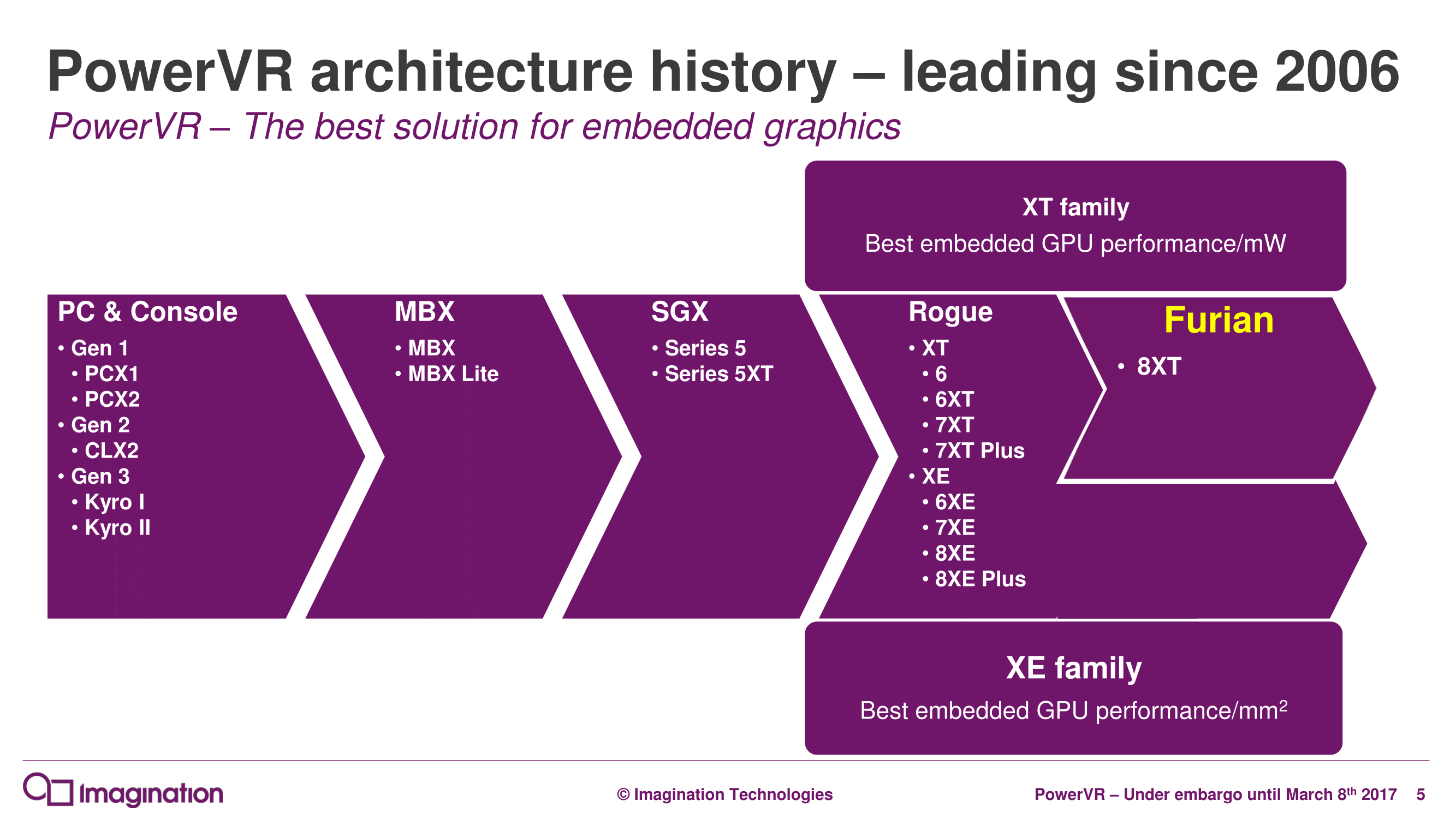
Initially, Furian will co-exist alongside Rogue designs. The initial designs for Furian will be high-end designs, which means that Rogue will continue to cover customers’ needs for lower power and area efficient designs. In particular, the various XE designs will still be around for some time to come as Imagination’s leading design for area efficiency. XE will eventually be replaced by Furian, but this could potentially be some years down the line due to a mix of design priorities, cost, and the fact that new architecture features can hurt the area efficiency of a design.
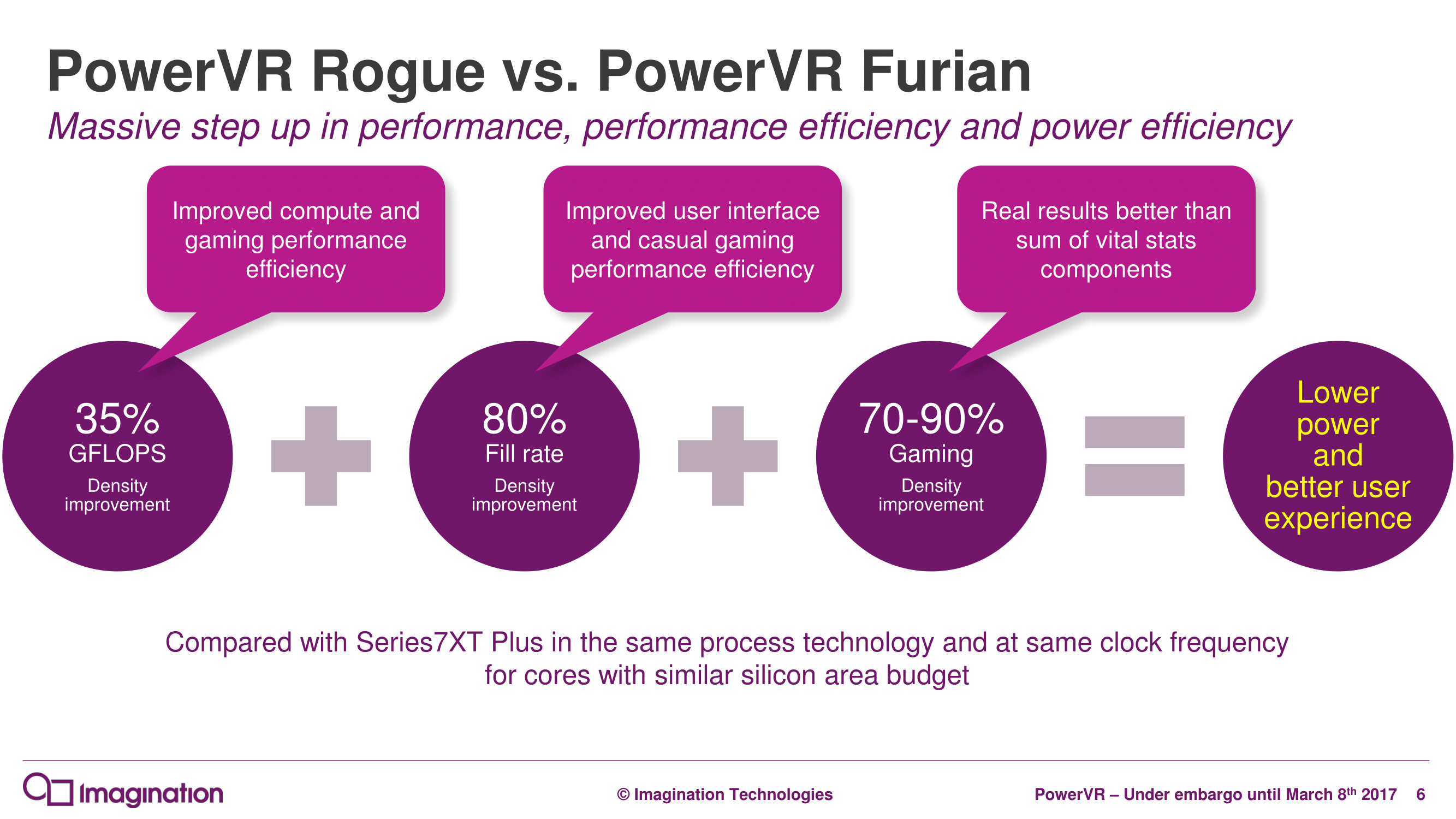
The ultimate goal of Furian is of course to improve power and performance, both on an energy efficiency (perf-per-milliwatt) and area efficiency (perf-per-mm2) basis. In fact it’s interesting that despite the fact that the first Furian designs will be high-end designs, Imagination is still first and foremost promoting area efficiency with Furian. Compared to a similarly sized and clocked Series7XT Plus (Rogue), Imagination is stating that a Furian design would offer 35% better shader performance and 80% better fill rate (though the company’s presentation doesn’t make it clear if this is texel or pixel), with an ultimate performance gain of a rather incredible 70-90%.
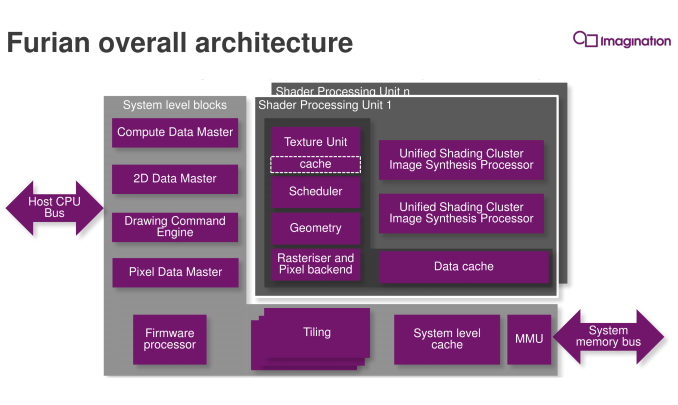
From an architectural standpoint Furian is not a new architecture designed from the ground-up, but rather is a rather significant advancement over what Imagination has already done with Rogue. We’re still looking at a Tile Based Deferred Rendering system of course – the bread and butter of Imagination’s GPU technology – with Imagination taking what they’ve learned from Rogue to significantly rework blocks at every level for better performance, greater capabilities, or better scaling. In fact the latter is a big point for the company, as this architecture ultimately needs to replace Rogue and last for a number of years, meaning a high degree of scalability is required. To do that, Imagination has essentially re-engineered their layout and data-flow for Furian – more hierarchical and less of a focus on a central hub – in order to ensure they can further scale up in future designs.
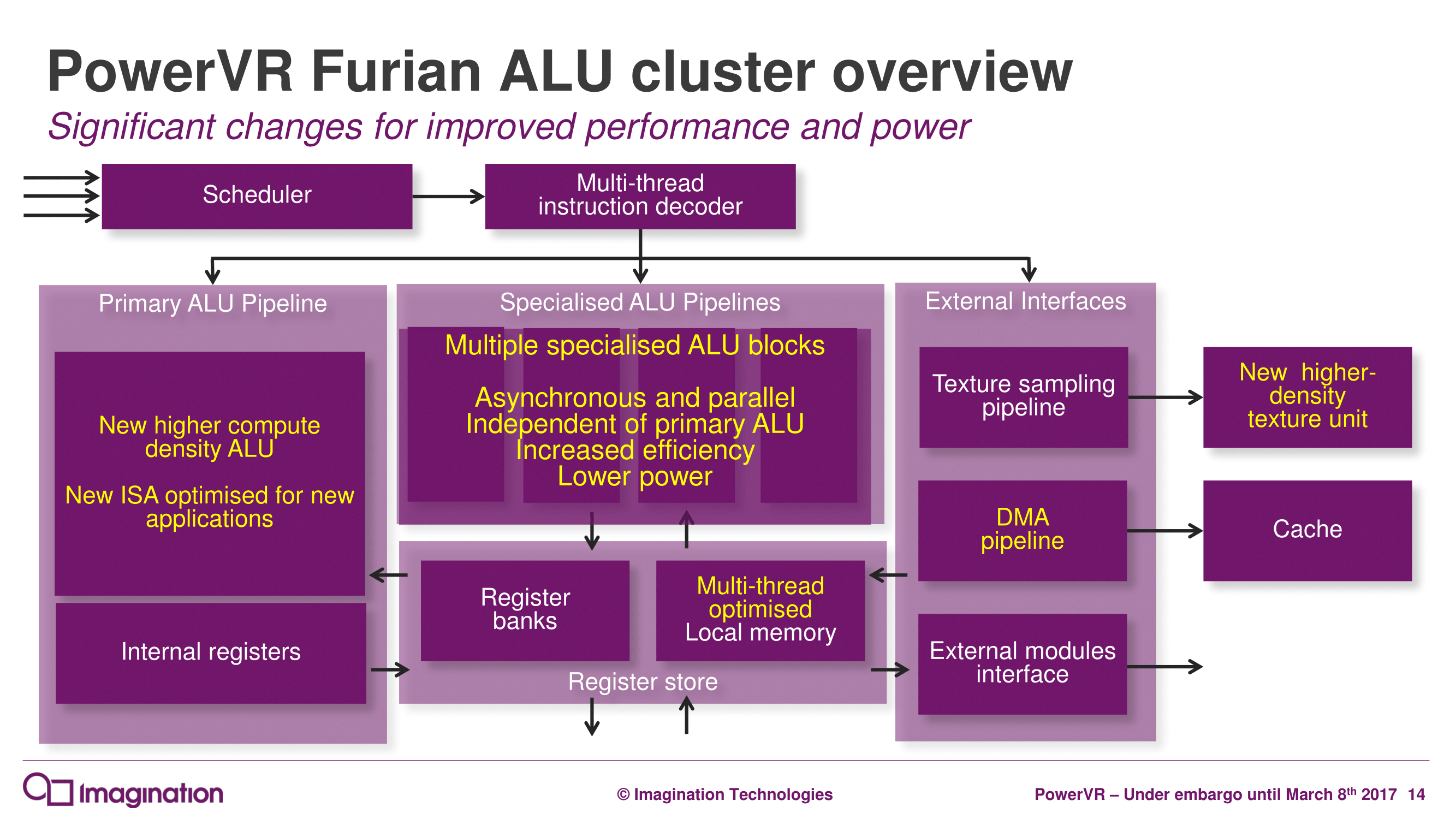
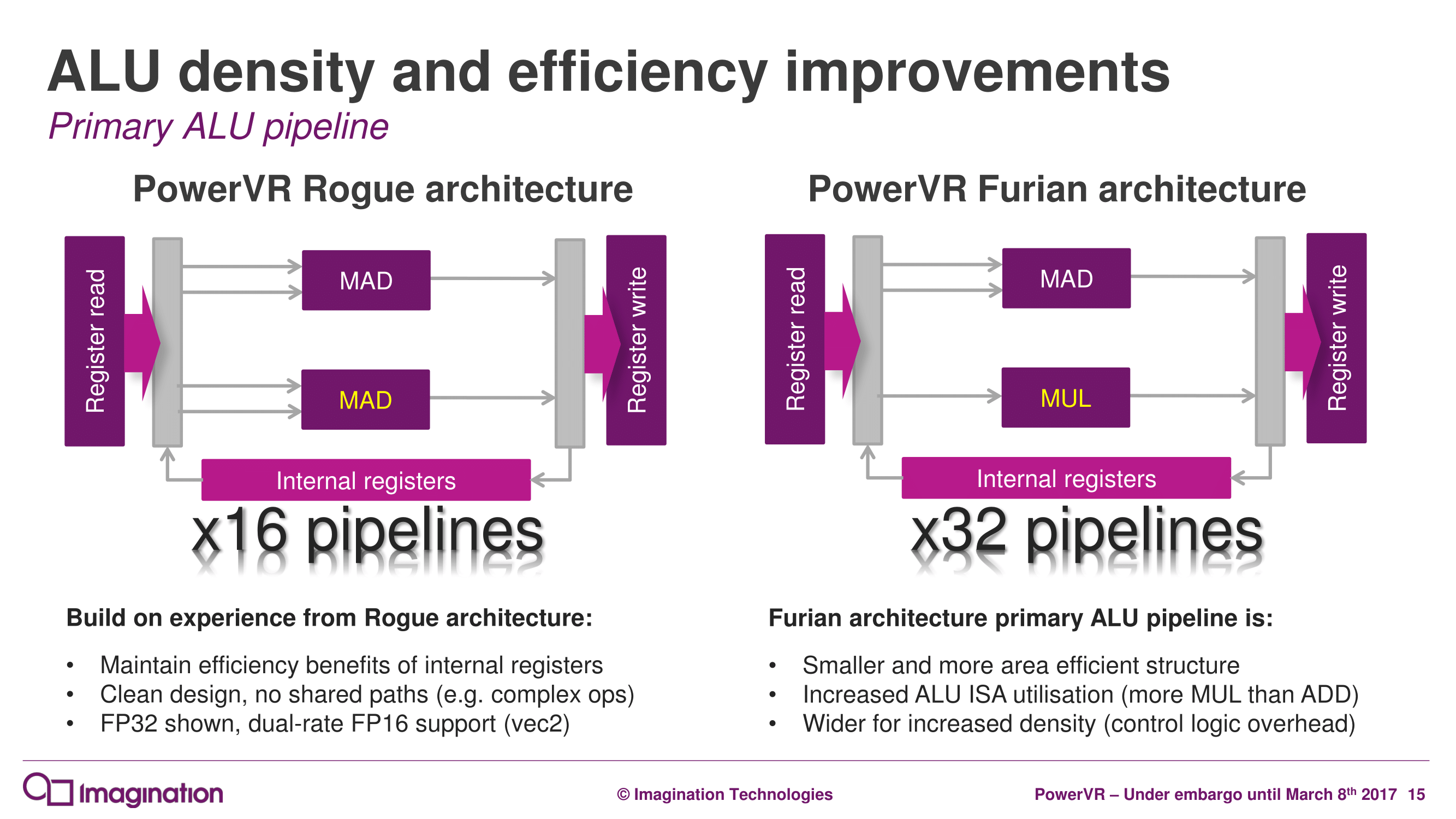
And as you’d expect for a new architecture, Imagination has made several changes under the hood at the ALU Cluster level – the heart of the GPU – in order to improve their GPU designs. The biggest change here – and I dare say most conventional – is that the company has significantly altered their ALU pipeline design. Whereas a full Rogue ALU would contain 16 pipelines per cluster, each composed of a number of ALUs of various sizes capable of issuing MADs (multiply + add), Furian takes things in a wider, less flexible direction.
For Furian, a single pipeline drops the second MAD ALU for a simpler MUL ALU. This means that the ALUs in a pipeline are unbalanced – the ALUs aren’t equal in capability, and you need to come up with a MUL to fill the second ALU. The advantage of a pair of matching MAD ALUs is that the resulting architecture is conceptually clean and simple. The problem is that relative to simpler MUL or ADD ALUs, MAD ALUs are bigger, more power hungry, and put more pressure on the register file.
Ultimately Imagination found that they were having a hard time filling the second MAD on Rogue, and a MUL, while not as capable, could cover a lot of those use cases while being simpler. The net effect is that the second MUL will likely be used less than the MAD, but it will pay for itself in size and power.
Meanwhile as mentioned before, Imagination is also expanding the size of a cluster, from 16 pipelines to 32 pipelines. Rogue’s native wavefront size was 32 to begin with – executing half a wavefront over 2 cycles – so this isn’t as big a change as it first appears, since the actual thread granularity doesn’t change. However with one cluster for 32 pipelines instead of two clusters for 32 pipelines, this cuts down on the amount of control logic overhead. At the same time, presumably in anticipation of Furian designs having fewer clusters than comparable Rogue designs, Imagination has increased the performance of the texture unit, going from 4 bilinear samples/clock on Rogue to 8 bilinear samples/clock on Furian.

At a higher level, the compute capabilities of Furian will easily exceed those of Rogue. The architecture is designed to be OpenCL 2.x capable (conformance results pending), and there will be variations that are fully cache/memory coherent for heterogeneous processing. On that note, while it’s not outright HSA compliant, Furian adopts many of the hardware conventions of HSA, so it should behave like other heterogeneous solutions.
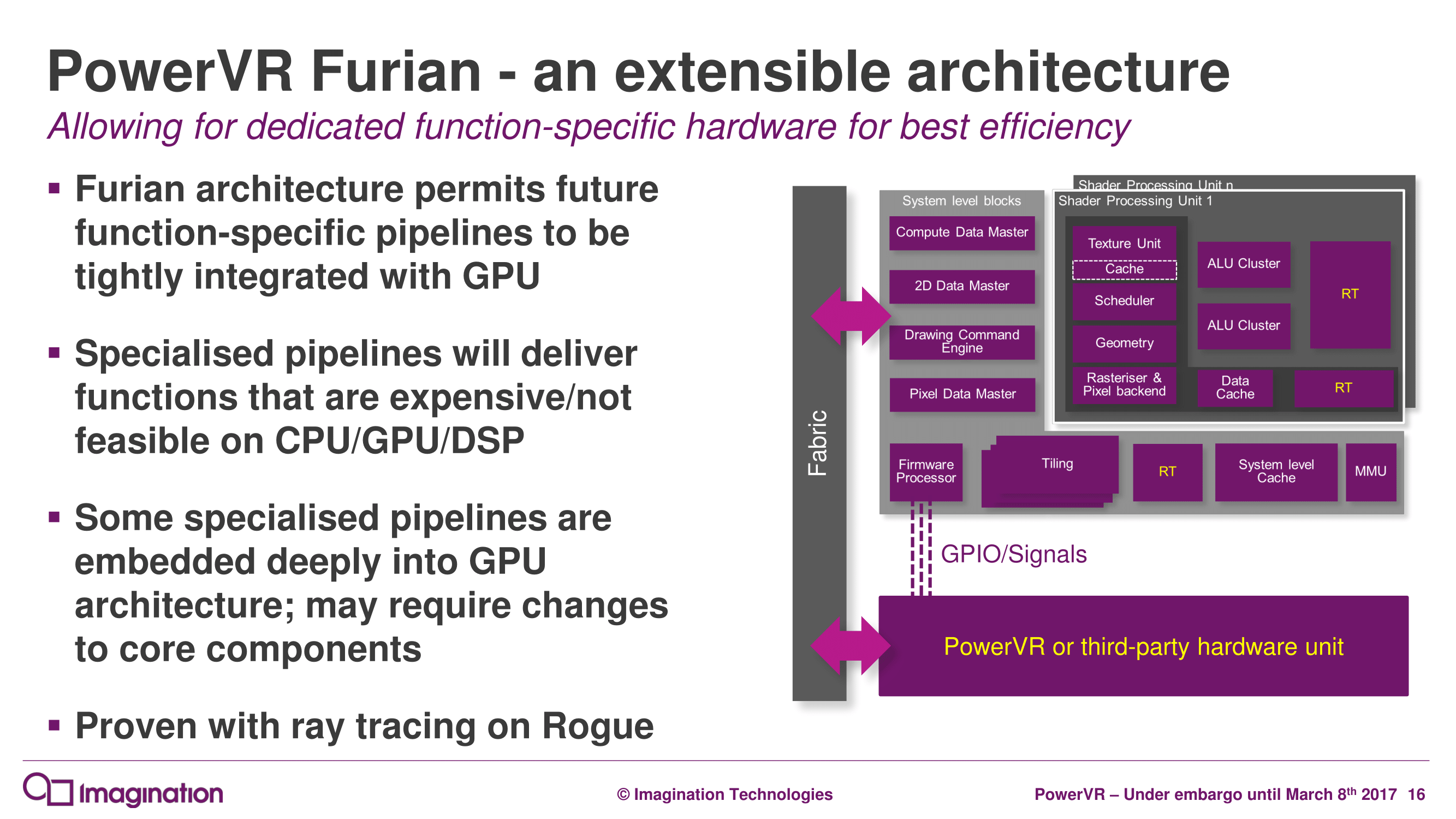
Though for more specialized workloads, in an interesting change Furian will be able to accommodate additional “function-specific” pipelines in customized GPU designs. How this is done is ultimately up to the customer – Imagination just provides the IP and reference RTLs – but the plumbing is there for customers to either add new functional hardware at the block level, or go as low level as the shader processor unit itself to add this hardware. The most obvious candidate here would be ray tracing hardware derived from Imagination’s Wizard architecture, but ultimately it’s up to the customers integrating the GPU IP and how much work they want to put in to add additional blocks.

Finally, once Imagination is shipping final Furian designs, the company will be courting customers and downstream users in all of the major high-end markets for embedded GPUs. Besides the obvious high-end phones and GPUs where they’ll go head-to-head with the likes of ARM’s Bifrost architecture, Imagination will also be going after the automotive market, the VR market, and thanks to the compute improvements, the rapidly growing deep learning market. The nature of IP licensing means that end-users are a couple of layers down, so Imagination first needs to court direct customers to build SoCs tailored to these applications, but the capability is there in the IP should customers demand it.
As for when we’ll see Furian designs in consumer hardware, that too is ultimately up to customers. Final Furian RTL designs will not be released to customers until sometime in the middle of this year, which is also why Imagination has not yet announced any specific GPU designs. As a result the lag time between announcement and implementation will be longer than past announcements, where the company was already announcing GPU designs with final RTL. Customers could potentially have Furian-equipped silicon ready towards the end of 2018 if they rush, but the bulk of the first-generation Furian products will likely be in 2019.












19 Comments
View All Comments
Demi9OD - Wednesday, March 8, 2017 - link
I've always wanted a Vin Diesel powered GPU.BrokenCrayons - Wednesday, March 8, 2017 - link
It seems like you'd end up with a lot of comically unrealistic car chase scenes if that were the case.fanofanand - Wednesday, March 8, 2017 - link
Well the article does mention that they are working on the automotive sectorjimjamjamie - Friday, March 10, 2017 - link
Camera DSP now includes night visionlilmoe - Wednesday, March 8, 2017 - link
"On that note, while it’s not outright HSA compliant, Furian adopts many of the hardware conventions of HSA, so it should behave like other heterogeneous solutions.""I’ll have a deeper dive into Furian next week"
Would you mind elaborating more on HSA capabilities by then? This might be a significant limiting factor of the new design, compared to Bifrost and the latest Adrenos, outside Apple's ecosystem that is.
name99 - Wednesday, March 8, 2017 - link
Imagination is part of the HSA Foundation. This suggests to me that f they are not "outright HSA complaint" the differences are legalistic rather than important. For example- they may not support HSAIL. (If they support SPIR for Vulkan & OpenCL and whatever Metal requires, why do they need HSAIL?)
- maybe some technical details about how HSA is supposed to interoperate with PCIe and external DRAM, which Imagination don't care about because all their target sales are to devices with a single pool of RAM, not split GPU and "main" DRAM?
Ryan Smith - Wednesday, March 8, 2017 - link
They do not support HSAIL.HomeworldFound - Wednesday, March 8, 2017 - link
Kill the Riddick!RaichuPls - Wednesday, March 8, 2017 - link
"I'll have a deeper dive into Furian next week"Will that be posted where the A10 deep dive, the 1050/1050 Ti reviews and the 980/970 SLI deep dive was posted?
tipoo - Wednesday, March 8, 2017 - link
I'm not usually one to complain about AT taking their time, but yeah, what's going on with Octobers A10 piece? If it's not happening can we just be told? Or if it is, what's the new ETA?