NVIDIA’s Maximus Technology: Quadro + Tesla, Launching Today
by Ryan Smith on November 14, 2011 9:00 AM ESTWhy Combine Quadro & Tesla?
So far we’ve covered how NVIDIA will be combining Quadro, but the more interesting question is “why?” In the NVIDIA hierarchy, Quadro is NVIDIA’s leading product. On the graphics side it’s fully unlocked, supporting quad-buffers, uncapped geometry performance, and uncapped viewport performance, while on the compute side it offers full speed FP64 support. Furthermore it’s available in the same configurations as a Tesla card, featuring the same number of CUDA cores and memory. Short of TCC, if you can compute it on a Tesla, you can compute it on a Quadro.
This actually creates some complexities for both NVIDIA and users. On a technical level, Fermi’s context switching is relatively fast for a GPU, but on an absolute level it’s still slow. CPUs can context switch in a fraction of the time, giving the impression of a concurrent thread execution even when we know that’s not the case. Furthermore for some reason context switching between rendering and compute on Fermi is particularly expensive, which means the number of context switches needs to be minimized in order to keep from wasting too much time just on context switching.
As a result of the time needed to context switch, Quadro products are not well suited to doing rendering and compute at the same time. They certainly can, but depending on what applications are being used and what they’re trying to do the result can be that compute eats up a great deal of GPU time, leaving the GUI to only update at a few frames per second with significant lag. On the consumer side NVIDIA’s ray-tracing Design Garage tech demo is a great example of this problem, and we took a quick video on a GTX 580 showcasing how running the CUDA based ray-tracer severely impacts GUI performance.
Alternatively, a highly responsive GUI means that the compute tasks aren’t getting a lot of time, and are only executing at a fraction of the performance that the hardware is capable of. As part of their product literature NVIDIA put together a few performance charts, and while they should be taken with a grain of salt, they do quantify the performance advantage of moving compute over to a dedicated GPU.
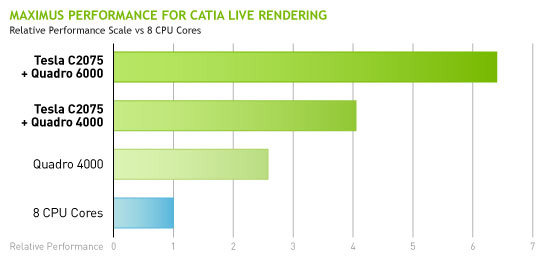
For these reasons if an application needs to do both compute and rendering at the same time then it’s best served by sending the compute task to a dedicated GPU. This is the allocation work developers previously had to take into account and that NVIDIA wants to eliminate. At the end of the day the purpose of Maximus is to efficiently allow applications to do both rendering and compute by throwing their compute workload on another GPU, because no one wants to spend $3500 on a Quadro 6000 only for it to get bogged down.
It’s worth noting that this situation closely mirrors the situation for software developers. For debug purposes NVIDIA recommends programmers have two GPUs, so that one GPU can be locked down debugging a compute or rendering task as necessary, while the other GPU is available to display the results. So NVIDIA encouraging users to have two GPUs for technical reasons is not new, but it is expanded. It also means there’s an obvious avenue for further development as NVIDIA wants to move GPU multitasking closer and closer to where CPU multitasking is today.
Moving on, the second reason NVIDIA is pursing Maximus is a result of their own actions. Because Quadro is NVIDIA’s leading product, it commands a leading price: a Quadro 6000 card is $3500 or more. This is a product of NVIDIA’s well engineered market segmentation – a GF110 GPU can be in a $500 GTX 580, a $2500 Tesla C2075, or a $3500 Quadro 6000. By disabling a few critical features on other products (e.g. geometry performance or FP64 performance) NVIDIA can push customers into buying a product at a price NVIDIA believes is best for the target market.
So what’s the problem? The Quadro 6000 is both a highly capable rendering product at a highly capable compute product, but not every professional user needs that much rendering power even if they need the compute power. Those users still need a Quadro card for its uncapped rendering performance, but they don’t necessarily need features such as Quadro 6000’s massive geometry throughput. The result is that NVIDIA was pricing themselves right out of their own market.
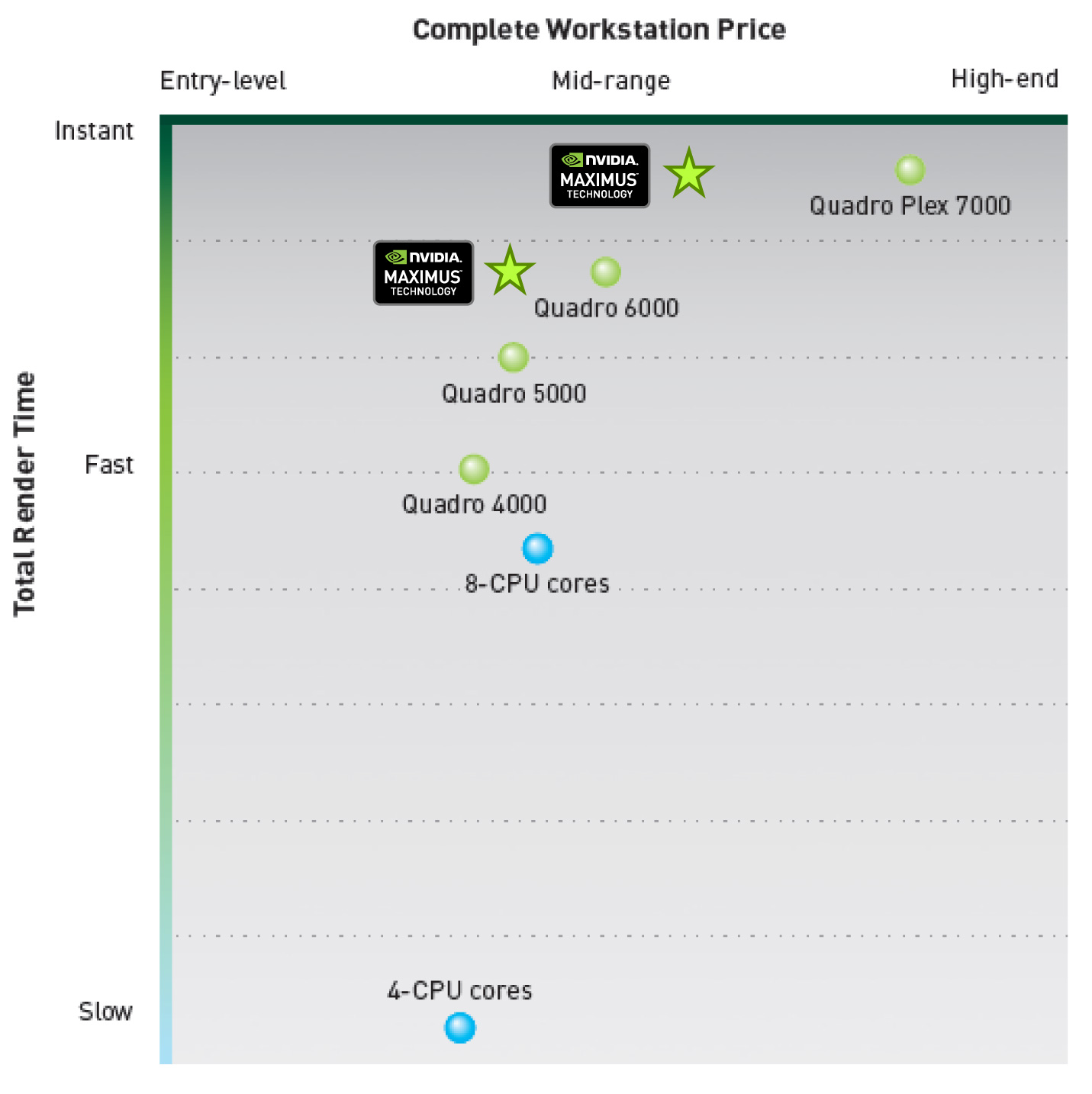
The solution to that is combining Quadro and Tesla. Maximus allows a Tesla C2075 to be used with any Fermi based Quadro (600/2K/4K/5K/6K), which allows NVIDIA to more appropriately tap the overlapping market of Quadro users that need top-tier compute performance. The end result for those users is that they not only pay less – a Quadro 2000 and a Tesla C2075 is $3000 versus over $3500 for a single Quadro 6000 – but they gain the aforementioned advantages of not having conflicting tasks slowing down the performance of a single Quadro card. Admittedly this is a lot of effort on NVIDIA’s part to tap a very specific market, but at the end of the day the professional market is a highly profitable market, making it worth NVIDIA’s time.
Final Words
Wrapping things up, NVIDIA has made it clear that they’re going to be pushing Maximus hard right out of the gate. Today of course was also the launch of Intel’s new Sandy Bridge E platform for high-end desktops and workstations, and in this industry there’s very little coincidence. It’s in NVIDIA’s interest to latch into workstation upgrade sales, and this is how you do it. They’ve already lined up HP, Lenovo, Fujitsu, and Dell to offer workstations pre-configured for Maximus, and we’re told those workstations will be made available for purchase today.
As to whether Maximus will be successful or not, this is going to depend both on software and marketing. On the software side NVIDIA needs to deliver on the transparency Maximus promises to developers and users – the concept is simple, but for the professional market the execution must be precise. Optimus graphics switching misbehaves now and then, but professional users will not be as willing to put up with any undesired behavior out of Maximus.
Marketing on the other hand is equally about promoting Maximus and promoting CUDA. A lot of NVIDIA’s promotional material for Maximus could easily be confused for CUDA promotional material, and this is because the videos and case studies are largely about how CUDA improved a process or a product while Maximus was the icing on the cake. Though we consider CUDA old, the fact of the matter is that much of the professional market NVIDIA is targeting has still not heard of CUDA, or has a limited understanding at best. As such NVIDIA will be using the launch of Maximus to promote the benefits of CUDA to certain targeted markets such as manufacturing, design, and broadcasting, just as much as they will be promoting the benefits of having multiple GPUs.








29 Comments
View All Comments
chandan1014 - Monday, November 14, 2011 - link
Can NVIDIA give us at least a timeline when to expect optimus for desktops? Current sandy bridge processors have powerful enough graphics unit for general computing and I really would like to see, let's say, a GTX 580 to power down when I'm surfing the web.GoodBytes - Monday, November 14, 2011 - link
You don't want Optimus.Optimus uses the system bus (which you only have 1 from the CPU to memory), to send rendered frame from the GPU to the Intel memory reserved space. As the bus can only be used by 1 at a time.. this means you'll get a large reduction in CPU power. Basically creating bottleneck. The more demanding the game, the less CPU power you have.. which will slow down the game, unless you kill anything from the game that uses the CPU.
This the major downside of Optimus.
If you want to control your GPU performance (which already does via Nvidia PowerMizer technology, which clocks the GPU based on it's work load), you can install Nvidia System Tools, and have look at Nvidia Control Panel. A new section"Performance" will appear and you can create profiles to switch form by double click on them, which has the performance specification set by you.
Or
you can use many overclock tools out there for your GPU, but instead of overclocking, you switch between normal default speed (let's say you don't want to overclock), and minimum speed, and switch between mode via keyboard shortcuts or something.
tipoo - Monday, November 14, 2011 - link
I've never seen any benchmarks indicating Optimus slows down the CPU when using the IGP, sauce pleaseGuspaz - Monday, November 14, 2011 - link
Sandy bridge has 21.2GB/s of memory bandwidth. It's a dual-channel system, not single-channel as you imply (both the PCIe and memory controllers are on-die on the CPU). Sending a 1080p image at 60Hz over that bus, uncompressed, would require ~0.35 GB/s of memory bandwidth (Double that, I suppose, to actually display it). I'm not seeing how this would have a major impact on a system that isn't anywhere near being memory bandwidth limited at the moment.MrSpadge - Monday, November 14, 2011 - link
Totally agree with Guspaz.And you'Ve got even more facts wrong: the amount of bandwidth needed for the frame buffer depends on display refresh rate and resolution, but not on game complexity.
MrS
Roland00Address - Monday, November 14, 2011 - link
And it was supposedly close to release in April, but then it wasn't heard from again.know of fence - Tuesday, November 15, 2011 - link
"Optimus for Desktops" headline made its rounds in April 2011, 6 month ago. Maybe after the next gen of cards or maybe after the holidays? It's time desktops get some cool tech instead of "super-size" technology (OC, SLI, multi monitor. 3D).Scalable noise & power has the potential to make Geforce Desktop PCs viable for general purposes again, instead of being a vacuum / jet engine.
Seriously with equal power consumption heat pumps are three to four times as efficient when it comes to room heating.
euler007 - Monday, November 14, 2011 - link
How about some Autocad 2012 Quadro drivers Nvidia?GTVic - Monday, November 14, 2011 - link
I believe Autodesk is moving away from vendor specific drivers. The preferred option for hardware driver in the performance tuner is just "Autodesk". If you have an issue with a Quadro driver on an older release of AutoCAD, Autodesk's official response will be to use the Autodesk driver instead. Autodesk certifies the Quadro and AMD FirePro drivers as well as drivers for consumer video cards.In the past, 2D users didn't generally turn on the Autodesk hardware acceleration, especially if you had a consumer level video card. With 2012 you almost have to turn on hardware acceleration because almost everything is now accelerated. You will see significant flickering in the user interface without acceleration. As a result Autodesk now needs to supports most consumer graphics cards out of the box and can't rely on a vendor specific driver.
With FirePro and Quadro what you are paying for is hopefully increased reliability and increased testing to ensure that the entire graphics pipeline supports the Autodesk requirements for hardware acceleration. In addition, Autodesk is more likely to certify Quadro/FirePro hardware with newer graphics drivers than if you purchase a high-end consumer card.
Filiprino - Monday, November 14, 2011 - link
How about some GNU/Linux support? You know, there's lot of compute power being used on GNU/Linux systems, and video rendering too.And finally, what about Optimus on GNU/Linux? NVIDIA drivers are ok on Linux based systems, but they're not complete as now there's no Optimus at all.