The AMD Zen 5 Microarchitecture: Powering Ryzen AI 300 Series For Mobile and Ryzen 9000 for Desktop
by Gavin Bonshor on July 15, 2024 9:00 AM EST- Posted in
- CPUs
- AMD
- Mobile
- Zen 5
- AM5
- XDNA 2
- Ryzen 9000
- Ryzen AI 300
- RDNA 3.5
- Radeon 890M
AMD Ryzen AI 300: XDNA 2 NPU with Up To 50 TOPS
When it comes to the AMD Ryzen AI 300 series for notebooks and laptops, the second biggest advancement from the previous Ryzen 8040 series (Hawk Point) is through the Neural Processing Unit (NPU). AMD, through their acquisition of Xilinx back in 2020, jump-started their NPU development by integrating Xilinx's existing technology, leading to AMD's initial XDNA architecture. With their latest iteration of the architecture, XDNA 2, AMD is further expanding on its capabilities as well as its performance. It also introduces support for the Block Floating Point 16-bit arithmetic approach as opposed to the traditional half-precision (FP16), which AMD claims to combine the performance of 8-bit but with the accuracy of 16-bit.

Looking at how the AMD XDNA architecture differs from the typical design of a multicore processor, the XDNA design must incorporate a flexible compute with an adaptive memory hierarchy. Compared to models of fixed compute or a model based on a static memory hierarchy, the XDNA (Ryzen AI) Engine uses a grid of interconnected AI Engines (AIE). Each engine has been architected to be able to dynamically adapt to the task at hand, including computation and memory resources, which are designed to improve scalability and efficiency.
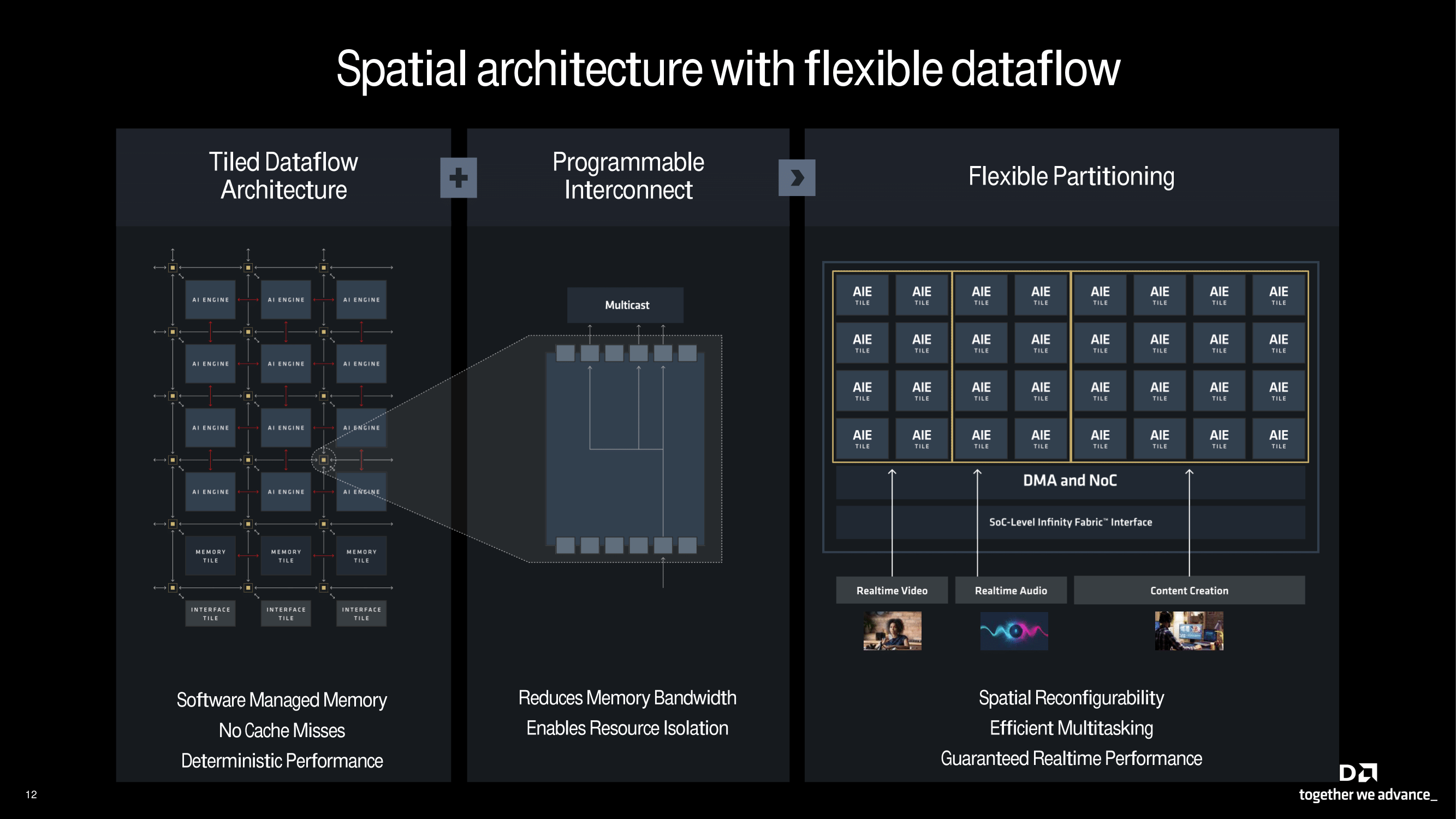
Touching more on the tiled approach to the AIE, AMD calls this spatial architecture. It is designed to be flexible, while it couples a tiled dataflow structure with programmable interconnection and flexible partitioning. The tiled dataflow structure enables deterministic performance without any cache misses and also enhances memory management. A programmable interconnect substantially decreases the demand for memory bandwidth, which allows it to allocate resources efficiently. The flexible partitioning design used enables real-time performance while being able to accommodate different requirements, from a variety of AI inferencing tasks, including real-time video and audio processing, to content-creation workflows.

The XDNA 2 architecture builds upon the preexisting XDNA architecture and adds even more AI engines to increase throughput. The AMD XDNA 2 implementation in Strix Point has 32 AI engine tiles, which is 12 more than the previous generation. Not only giving more AI engine tiles, the XDNA 2 architecture also has double the number of MACs per tile and 1.6 X more on-chip memory than the previous generation.
All told, AMD is claiming 50 TOPS of NPU performance, which is more than Intel and Qualcomm's current offerings. The debate around the relevancy of using TOPS to measure AI performance is divisive, and Microsoft set the ball rolling on that one by setting the bar for Copilot+ at 40 TOPS.

Not just about trying to outdo the competition on TOPS, but the XDNA 2 architecture is also designed with power efficiency in mind. AMD claims that its XDNA 2 NPU provides 5x the compute capacity at double the power efficiency compared to the NPU used in the Ryzen 7040 Series. This is made possible through various design choices, including the column-based power gating that AMD says it offers significantly better battery life with the ability to simultaneously handle as many as eight concurrent spatial streams when multitasking.

One of the major feature inclusions with the XDNA 2 architecture is support for the Block Floating Point (Block FP16). The simple way to explain what it does is it offers the performance and speed of 8-bit operations, but employs additional tricks to try to bring the precision closer to 16-bit operations. Notably, this is also done without further quantization or reducing the data size being processed.
As with other neural network precision optimizations, the purpose of Block FP16 is to cut down on the amount of computational work required; in this case using 8-bit math without incuring the full drawbacks of stepping down from 16-bit math – namely, poorer results from the reduced precision. Current generation NPUs can already do native 8-bit processing (and 16-bit, for that matter), but this requires developers to either optimize (and quantize) their software for 8-bit processing, or take the speed hit of staying at 16-bit. AI is still a relativley young field, so software developers are sitll working to figure out just how much precision is enough (with that line seeming to repeatedly drop like a limbo bar), but the basic idea is that this tries to let software developers have their cake and eat it, too.
With all of that said, from a technical perspective, Block FP16 (aka Microscaling) is not a new technique in and of itself. But AMD will be the first PC NPU vender to support it, with Intel's forthcoming Lunar Lake set to join them. So while this is a new-to-AMD feature, it's not going to be a unique feature.
As for how Block FP16 works, AMD's own material on the subject is relatively high-level, but we know from other sources that it's essentially a form of fixed point 8-bit computation with an additional exponent. Specifically, Block FP16 uses a shared exponent for all values, rather than each floating point value having its own exponent. For example, rather than a FP16 number having a sign bit, 5-bit exponent, and 10-bit significant, you have an 8-bit exponent that's shared with all numbers, and then an 8-bit significand.
This essentially allows the processor to cheat by processing the unique significands as INT8 (or fixed-point 8-bit) numbers, while skipping all the work on the shared exponent. Which is why Block FP16 performance largely matches INT8 performance: it's fundamentally 8-bit math. But by having a shared exponent, software authors can move the whole number range window for the computation to a specific range, one that would normally be outside of the range offered by the puny exponent of a true FP8 number.
Most AI applications require 16-bit precision, and Block FP16 addresses this requirement by simultaneously bringing high performance and high accuracy to the mobile market, at least from an AI standpoint. This makes Block FP16 a very important component for pushing forward AI technology, and it is something AMD is pushing hard on.
Ultimately, the XDNA 2-based NPU in the Ryzen AI 300 series of mobile chips is really about processing AI workloads and running features such as Microsoft Copilot+ in a more power-efficient manner than using the graphics. And by being able to deliver 8-bit performance and 16-bit precision, that gives developers one more lever to pull to get the most out of the hardware.
The AMD XDNA 2 architecture, which is set to debut with the Ryzen AI 300 series, is going to provide the key to unlocking the AI PC, or at least what Microsoft defines with their 40 TOPS requirement for Copilot+. By bringing Block FP16 into the equation, AMD brings (close to) 16-bit accuracy at 8-bit speed, making it more performant for some AI applications. Altogether, the integrated NPU is slated to offer up to 50 TOPS of compute performance.
AMD was the first x86 SoC vendor to include an NPU within their chips, and with the growing need for on-chip AI solutions to unlock many software features, they're expecting the hardware (and the die space it represents) to be put to good use. The XDNA 2 architecture ensures that AMD remains at the forefront, offering solid levels of performance and combined versatility for the mobile market.








43 Comments
View All Comments
kpb321 - Monday, July 15, 2024 - link
I do like that they are dialing back the TDP on these chips some. The 7000 desktop chips seems to push that a little too hard to be the fastest. A little too much of the Intel overclocked to the edge from the factory there. Nice to see them backing down from that so we don't start seeing issues similar to the i9's.Gavin Bonshor - Monday, July 15, 2024 - link
AMD doesn't need to push higher wattages, which makes them more attractive from a perf/watt standpoint.Kangal - Tuesday, July 16, 2024 - link
What would have REALLY been impressive is if AMD had also designed, announced, and released an AM5p Motherboard Platform. Something that is similar to the Desktop AM5 Motherboards but this time it is for Laptops, with the key feature being accessibility. So that can upgrade the CPU, RAM, SSD as the months go on. And maybe even a socket for dGPU.I am aware of the Frameworks Laptop, but it would have been much better having this come directly from AMD. It would have really separated AMD as a premium option for laptops, against a walled/locked Intel platform, or the competitive ARM options coming in the future.
Just like how it was a massive upgrade to go from the first 8-core (r7-1700) to the last 8-core (r9-5800x3D) option on the AM4 Platform. It would have been great to see that on their AM4 Laptops (eg 4-core to 4-core for efficiency). But I understand that. Does not mean it cannot happen for AMD Laptops with this AM5 Platform though.
So yeah, AM5p Motherboards.... let's do that please!
zamroni - Tuesday, July 16, 2024 - link
I'd love to get those components user upgradable but soldered components reduces overall hardware production costs.you also can't get unsoldered lpddr, which is also faster than dimm ddr.
as long as the ssd is removable and 2280 slot spec, I'm fine with it.
i just wish all laptop manufacturers give option not to include windows.
i saw in hp website that it reduces the price by at least 100 dollar for the elite book model
TheinsanegamerN - Tuesday, July 16, 2024 - link
They could get around that with CAMM, which is modular but offers LPDDR speeds.Hifihedgehog - Tuesday, July 16, 2024 - link
Indeed. This is the trajectory of the market: CAMM. All of the benefits of lower power and higher frequencies of LPDDR memories with the added benefit of user upgradability. Link below:https://www.techpowerup.com/322754/lpddr6-lpcamm2-...
TheinsanegamerN - Tuesday, July 16, 2024 - link
I'd love it, unfortunately the world is moving more to throw away soldered designs, because screw reparability, upgradeability, or what some consumers want.Hifihedgehog - Tuesday, July 16, 2024 - link
https://www.techpowerup.com/322754/lpddr6-lpcamm2-...Terry_Craig - Tuesday, July 16, 2024 - link
In fact CAMM2 offers the best of both worlds.Silver5urfer - Tuesday, July 16, 2024 - link
Intel screwed up does not mean AMD's Arch also follow same. AMD's Zen 3 processors ran at 1.4V, Intel Sandy to SKL all ran at 1.4V. None of them exhibit the damn instability or the degradation to the point of no return.AMD needs to step up their TDP and wattage, the 9950X barely beats a 7950X. It's mediocre 41K CBR23, vs Zen 4's 38K. Compare to the Zen 3 vs Zen 4, the jump was over 14000points in CBR23.
AM5 socket is capped to 230W, no amount of PBO will exceed that. And PBO added Zen 4 goes to 40K and Zen 5 with Curve Shaper and PBO2 it will go upto 45K max.
AMD could have added more power, 50W for the R9, 25W for the R7 but they instead reduced it massively and also cut down the Base Clocks by a lot of MHz. Wonder if it's due to Intel's ARL dropping SMT / Hyperthreading.